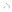Today we are pleased to announce the release of Elasticsearch 7.4.0, based on Lucene 8.2.0. Version 7.4 is the latest stable release of Elasticsearch, and is now available for deployment via Elasticsearch Service on Elastic Cloud.
Elasticsearch 7.4 features a number of improvements to core search and analytics capabilities, cluster management and administration, and operational resource efficiency. In addition, Elasticsearch 7.4 includes some new experimental features: one helps you find relationships within your data and another builds upon Elasticsearch’s growing capability to enhance search result relevance through the use of vectors.
If you’re interested in learning more about “what’s new,” stick around — we dive deeper into many of the release highlights below. Alternatively, if you’d rather “jump right in” by spinning up a cluster on Elastic Cloud, downloading the latest bits to your laptop, or reviewing the release notes:
Version 7.4 augments core search and analytics capabilities in Elasticsearch through the introduction of several new features. We’ve added native results pinning functionality (similar to the functionality available in Elastic Site Search) into our Basic (Elasticsearch) offering. Elasticsearch 7.4 also takes a large step towards better handling of geospatial search and analysis, and introduces two powerful new aggregations.
Occasionally administrators want to promote specific results by dictating the exact order of documents on a results page, or they may want to manually revise the results returned by a specific query. Historically, users managed result ordering by writing custom code in the application layer. With the release of 7.4, this is now possible directly within Elasticsearch, using results pinning. By using the new pinned query, users can manage and order results as they see fit.
Results pinning is released under Elastic’s free Basic license.
Previous investments in infrastructure for geospatial data — the introduction of BKD Trees — allowed us to introduce bkd-backed geopoints in Elasticsearch (and later bkd-backed geoshapes in 6.6). We are now building upon this foundation to simplify how geospatial data is processed, support new use cases, and improve performance.
Prior to Elasticsearch 7.4, users were required to represent their spatial data using earth’s coordinate system in the geo_shape field type. With this release we are happy to introduce a new shape field type that enables users to position and query in x, y coordinate systems of their own choosing – whether it is for use cases like a shopping center, computer aided design (CAD) diagrams, or virtual worlds (think: video games, cyber / network mapping) or for handling any other data that is positioned on an arbitrary two dimensional coordinate system. Prior to Elasticsearch 7.4, users were required to represent their spatial data using earth’s coordinate system.
We are also happy to announce the introduction of the circle ingest processor. Before today, when ingesting and indexing a circle into Elasticsearch, users had two options:
The new circle ingest processor translates circles into polygons that closely resemble them as part of the ingest process, which means ingesting, indexing, searching, and aggregating circles, just became both easy and efficient.
Note that creation of the polygon is a balancing act of sorts. The more edges the polygon has, the greater portion of the circle it will cover (more edges results in higher accuracy). However, as the number of edges increases, so too does the size of the index. We provide users with the ability to balance accuracy against the index size through a configurable error_distance parameter. To gain a better understanding of the relation between the number of sides of the polygon (impacting index size) and the size of the circle, you can examine the table we provided in the documentation, that illustrates several examples of circle radius and number of edges, with the error_distance kept to 1.
The new shape field type and circle ingest processor are released under Elastic’s free Basic license.
Previously, aggregations were not supported for range fields. With the release of Elasticsearch 7.4 we’re introducing support for running aggregations (Cardinality, Missing, Value Count, Histogram, and Date Histogram) on range fields. The ability to run Histogram and Date Histogram aggregations on range fields enables users to more easily count the number of ranges which overlap with specific buckets. For example, the date histogram aggregation on a range field enables users to count the number of phone calls which took place during a specific minute or to count the number of employees on vacation on a given day.
Also new with the release of Elasticsearch 7.4, the cumulative cardinality aggregation has been introduced as part of our ongoing efforts to provide advanced aggregations. This newly added pipeline aggregation allows users to calculate net new occurrences within a given time range. For example, this functionality enables a user to calculate the number of unique visitors to a site over a given time period without requiring additional filters or steps to deduplicate entries.
Cumulative cardinality aggregation is being released under Elastic’s free Basic license.
The best solutions help users to do more than just “keep the lights on” by being easy to configure, easy to maintain, and, with any luck, easy to readily address evolving business needs. To this end, Elasticsearch 7.4 introduces snapshot lifecycle management (SLM) and new cluster privileges to more efficiently manage API keys.
Snapshot lifecycle management is a background snapshot manager that enables an administrator to define when and how often automatic snapshots of an Elasticsearch cluster are taken. This ensures appropriate, recent backups are ready and available should the need arise to restore. Prior to Elasticsearch 7.4, users often solved snapshot management using third party tools or custom code. Users are now able to reduce tool proliferation by managing automatic snapshot lifecycle policies via API or via a new policy management UI (located within the snapshot and restore interface in Kibana) (see image below). The user interface in Kibana allows users to create, view, edit, and run policies for either the entire cluster or for specific indices.
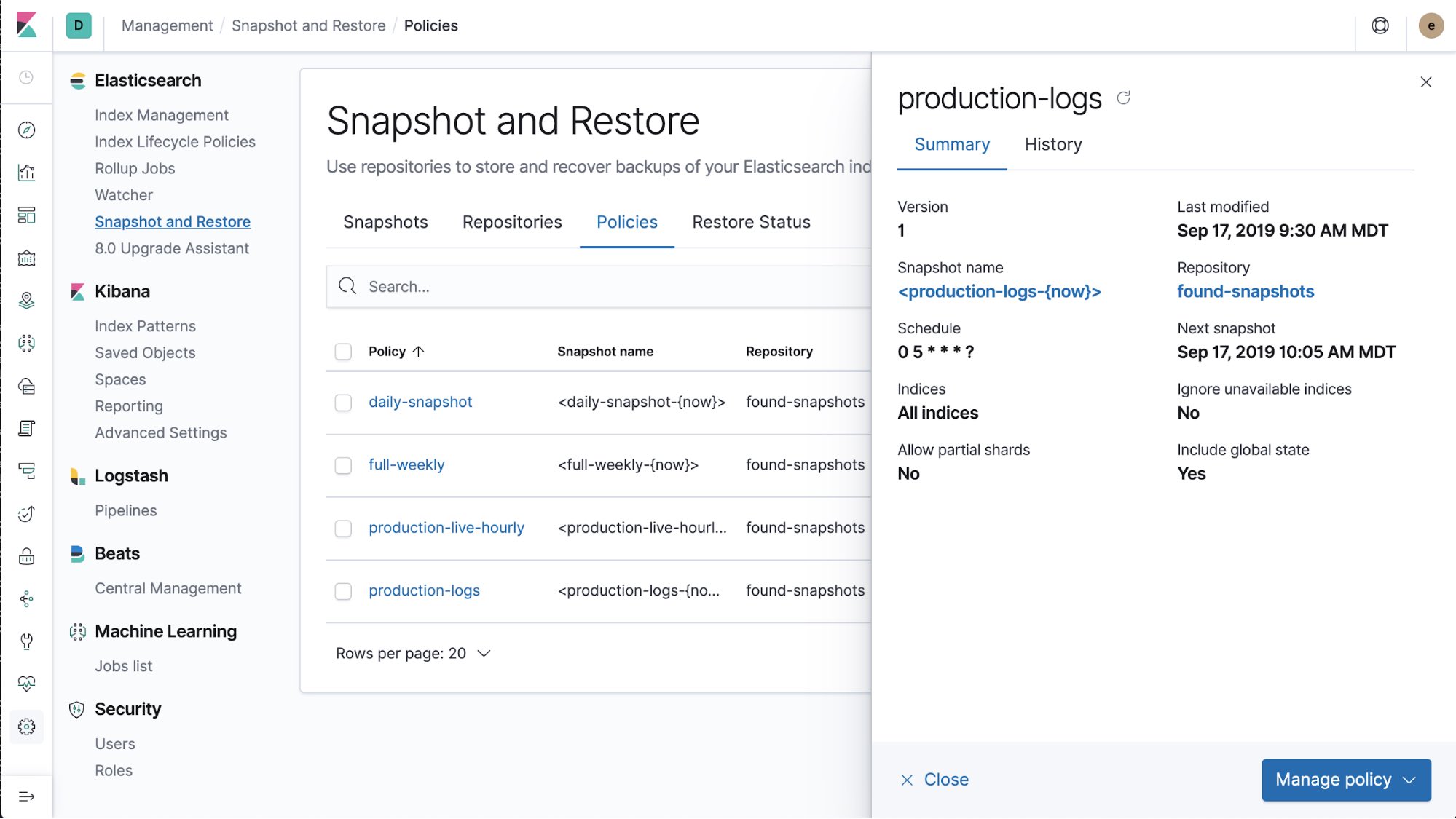
Snapshot lifecycle management is being released under Elastic’s free Basic license.
In 7.4, Elasticsearch is introducing new cluster privileges to manage API keys — allowing cluster administrators to manage everything, and other users to manage their own keys. Users can create API keys and use them to provide long-term credentials while interacting with Elasticsearch. This capability is especially useful when working with automated scripts, or workflow integration with other software.
These enhancements to API key management are being released under Elastic’s free Basic license.
Notifications may contain sensitive information that must be protected over the wire. This requires that communication with the mail server is encrypted and authenticated properly.
In 7.4, Elasticsearch supports custom TLS settings for email notifications, allowing secure connections to servers with custom security configuration.
AdoptOpenJDK 13 is now supported and will ship with Elasticsearch as the pre-bundled JDK (as always, if you want to bring your own JDK, you can still do so by setting `JAVA_HOME` before starting Elasticsearch). The availability of a notarized AdoptOpenJDK package (per the new requirements for software running on macOS Catalina) will facilitate notarization of Elasticsearch for continued support on macOS.
The team at Elastic is always working to improve the operational resource efficiency of Elasticsearch. This means tuning its performance so as to consume fewer resources and do more with less. Elasticsearch 7.4 certainly sees some goodness to these ends.
Historically, if a user wanted to terminate a client initiated query, this had to be done using the task management API. The new automatic query cancellation feature will automatically terminate queries sent through the _search endpoint when the initiating connection is closed.
Translog entries are no longer needed for shard recoveries. This can significantly reduce the amount of storage needed for the translog. Previously, a default of 512 MB or up to 12 hours of entries could be stored (per shard) for a recovery event. Since all new indices in Elasticsearch enable soft-deletes by default (starting with Elasticsearch 7.0), Elasticsearch 7.4 will use soft-deletes (when enabled) for shard recoveries instead of the translog. More information on translog retention can be found in the Elasticsearch 7.4 documentation.
Both automatic query cancellation and the translog improvements are being released under the Apache 2.0 license.
Note / (fair) warning: experimental features are… experimental. They’re NOT ready for “prime time” and may be changed or removed completely in a future release. Elastic will, of course, make an effort to fix major issues, but experimental features are not subject to Elastic’s support SLA for official, generally available features. That being said, should you elect to experiment with them (see what we did there?), please do send us your thoughts and feedback!
Regression analysis is a machine learning process for estimating the relationships among a number of feature variables and a dependent variable, then making further predictions based on the described relationship.
Regression analysis is being released as an experimental feature under Elastic’s Platinum license.
There are many scenarios in which vector similarity serves to measure document similarity. These can range from documents that are vectors to a variety of algorithms that represent a document — this could be an image or a text — as a vector. Recently, in Elasticsearch 7.3, we introduced the dot product and cosine similarity functions. Now, with the release of Elasticsearch 7.4, we are introducing two new vector similarity measurements:
Like the dot product and cosine similarity functions, the Euclidean and Manhattan distances are provided as predefined Painless functions so that they may be incorporated with other query elements as part of a script_score query.
Both new vector distance functions are being released as experimental features under Elastic’s free Basic license.
While the above listed features might have taken the spotlight, there were many more features included with the release of Elasticsearch 7.4 – be sure to check out the release notes for additional information.
Ready to get your hands dirty? Spin up an Elasticsearch cluster on Elastic Cloud or download Elasticsearch today. Try it out. And be sure to let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.